Fuzzing µC/OS protocol stacks, Part 1: HTTP server fuzzing

This is the first post of a three-part series, where we will be delving into the intricacies of fuzzing µC/OS protocol stacks. The techniques I will discuss are universally applicable to various RTOS environments, though our focus will primarily be on µC/OS.
I’ll highlight some of the strategic code modifications I implemented across different µC/OS components. The objective is to streamline the process of developing a fuzzing harness tailored for the µC/HTTP-server. In the second installment of this series, I’ll discuss a technique that I used for delivering multiple requests per fuzz test case. The third post will be like this one, as I’ll describe the code modifications that I made with the aim of fuzzing the µC/TCP-IP stack.
For a bit of context, µC/OS is an RTOS, or “Real-Time Operating System.” An RTOS is a specialized operating system designed to manage hardware resources and host applications that need to run in systems where timing is critical, such as in embedded systems, medical devices, or industrial controls. RTOSes haven’t been fuzzed as thoroughly as software that runs on desktop operating systems, primarily due to the complexities associated with setting up a fuzzing harness for these systems.
Developing a harness for an RTOS requires more coding effort than what is typically required for a straightforward, single-line fuzzing harness used with desktop applications or libraries.
Any vulnerability in an RTOS has the potential to affect many devices across multiple industries. It’s important to put these codebases through the same rigorous testing as is common for desktop operating systems. My hope is that the techniques described in this blog post series will encourage more widespread use of fuzzing of RTOS software components.
Historically fuzzing RTOS code involved a custom hardware setup to fuzz the code in its native environment, or fuzzing on an emulated version of the system. However, when Weston Embedded made the full µC/OS source code openly available in 2020, it sparked my curiosity about whether there could be a less complex approach to fuzz this type of code.
The goals for my fuzzer are:
- Use a modern fuzzing framework (I chose AFL++).
- Modify the networking code to accept input from a file.
- Handle multiple requests per test case (more on this in part 2).
Additionally, the constraints (self-imposed) for my HTTP fuzzer are:
- A software-only solution.
- Run natively on Linux.
With that in mind, I wanted to avoid using emulation or dedicated hardware for my fuzzer.
Linux port
To make use of a modern fuzzing framework like AFL++, I needed to write some code that would allow the µC/HTTP-server to operate on Linux instead of the native µC/OS kernel. However, I had to give some thought to what exactly I wanted my fuzzer to target and determine appropriate insertion points for my hooks that would enable this protocol implementation to run on Linux.
Below is a basic architecture diagram showing the software component structure of a µC/HTTP-server application. The blue highlight represents the components that I will be modifying to port the application to Linux. The orange highlight represents the code which is the target for the fuzzer.
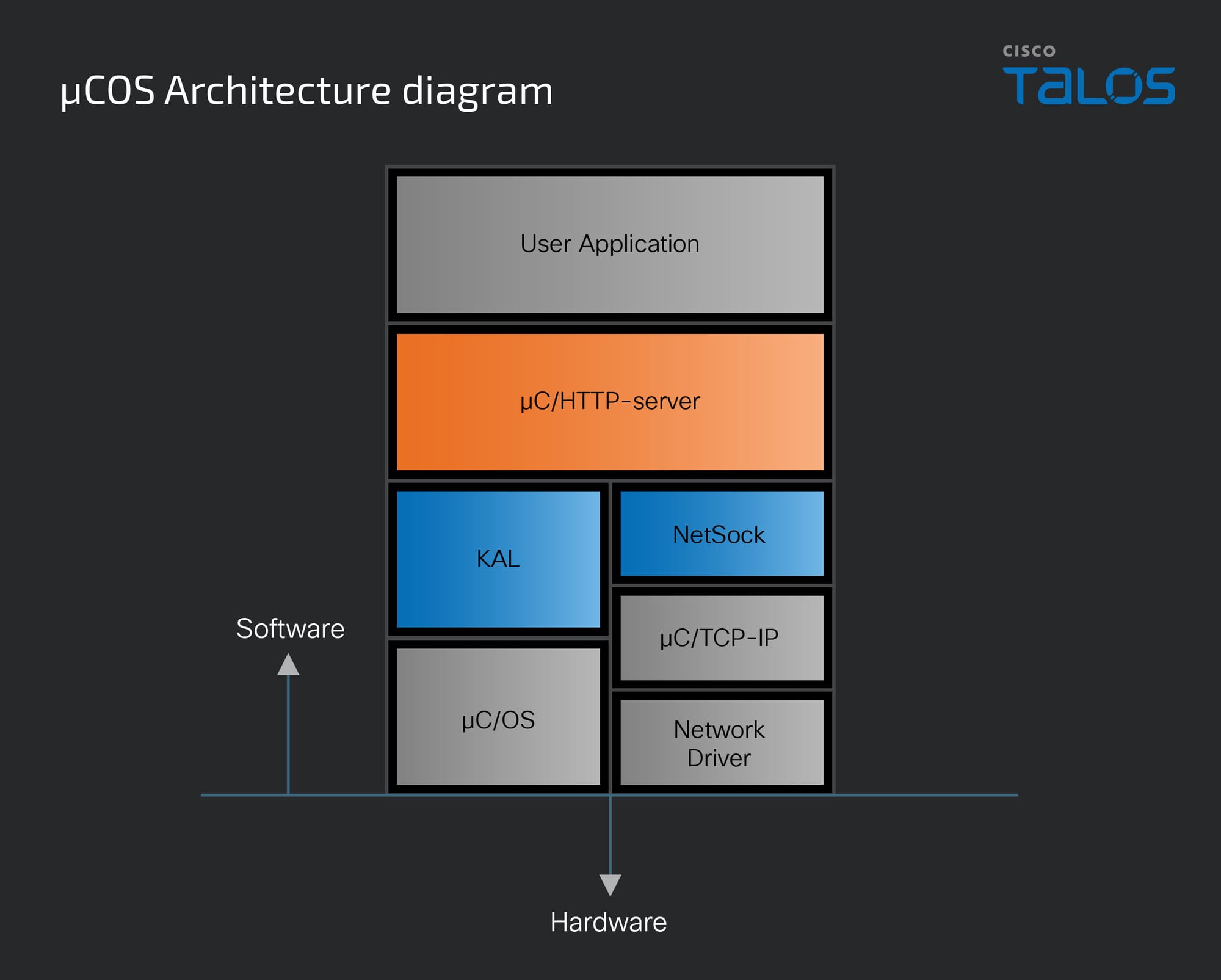
The modular design of µC/OS makes it wonderful to work with for this type of fuzzing. The Kernel Abstraction Layer (KAL in the diagram) provides a common API that is utilized by each of their libraries. This makes it easy to create a custom KAL that either mimics the desired RTOS functionalities for my fuzzer or simply returns a success signal for features that aren't relevant to the fuzzing process. Although µC/OS provides a POSIX-compatible KAL that enables the µC/HTTP-server to run on Linux, I chose to create my own KAL interface to simplify the entire setup.
The KAL lays out an API blueprint for operating system components like task management, locks, semaphores, timers, and message queues. In the case of µC/HTTP-server, the only KAL function it calls is KAL_TaskCreate, which means I only needed to implement this particular function in my custom KAL interface. Additionally, since the task in question is the main HTTP processing loop, I found a workaround by directly invoking the function itself within the KAL_TaskCreate function, bypassing the need for a more complex task creation process. Example code below:
void KAL_TaskCreate (KAL_TASK_HANDLE task_handle,
void (*p_fnct)(void *p_arg),
void *p_task_arg,
CPU_INT08U prio,
KAL_TASK_EXT_CFG *p_cfg,
RTOS_ERR *p_err)
{
/* return success */
*p_err = RTOS_ERR_NONE;
/* fake it and call the function */
p_fnct(p_task_arg);
return;
}Networking port
Socket reads
Much like the Linux port mentioned earlier, there is a network abstraction called NetSock within µC/OS's TCP/IP protocol suite which is like a POSIX socket in its functionality. For the purposes of this fuzzing project, my attention isn't on probing the underlying TCP/IP stack; instead, I'm focused on the µC/HTTP-server code. To ensure that the fuzzing input is fed directly to the µC/HTTP-server code without first passing through the TCP/IP code, I created a custom NetSock implementation.
My ultimate goal for this fuzzer is to read network data from a file. However, it will simplify the testing and debugging process to use existing tools to send real network traffic to my application. Once my µC/HTTP-server application is working enough to load a web page in a browser, it shouldn’t be too difficult to redirect protocol data from a file.
I decided to implement a NetSock to POSIX socket port. All that was required to do that was to call the POSIX counterpart within the NetSock API and return an appropriate µC/OS error code. Below is example code demonstrating receiving data from a socket:
NET_SOCK_RTN_CODE NetSock_RxData (NET_SOCK_ID sock_id,
void *p_data_buf,
CPU_INT16U data_buf_len,
NET_SOCK_API_FLAGS flags,
NET_ERR *p_err)
{
*p_err = NET_SOCK_ERR_NONE;
ssize_t recvLen = 0;
recvLen = recv(sock_id, p_data_buf, data_buf_len, 0);
if (recvLen < 0)
{
*p_err = NET_ERR_RX;
return NET_SOCK_BSD_ERR_RX;
}
else if (recvLen == 0)
{
*p_err = NET_SOCK_ERR_RX_Q_EMPTY;
}
return recvLen;
}
I then repeated this process for each of the NetSock_* functions. I used the correct NetSock_* function signature, called the corresponding POSIX socket function call and then returned an error code that was of the type NET_SOCK_RTN_CODE.
File reads
With my µC/HTTP-server application now properly responding to HTTP requests, the next step was to set it up for fuzzing by having the NetSock code read from a file instead of a real POSIX socket. There are a few different options of how to achieve reading from a file. The first is using a tool called libdesock. The way that file redirection works with this tool is that the library gets loaded by the Linux linker before other libraries by using LD_PRELOAD. This allows the libdesock library to intercept POSIX socket calls and redirect them to stdin and stdout.
Since I was already well acquainted with modifying the NetSock code, another simple approach is to read from a file instead of calling recv within NetSock. To implement this, my µC/HTTP-server application takes a file name as an argument and stores a file pointer to that file in a global variable named curr_inputfd. Below is an example of “receiving” data from a file:
NET_SOCK_RTN_CODE NetSock_RxData (NET_SOCK_ID sock_id,
void *p_data_buf,
CPU_INT16U data_buf_len,
NET_SOCK_API_FLAGS flags,
NET_ERR *p_err)
{
ssize_t totalLen = 0;
*p_err = NET_SOCK_ERR_NONE;
totalLen = read(curr_inputfd, (char*)p_data_buf, data_buf_len);
if (0 > totalLen)
{
/* return an error */
*p_err = NET_ERR_RX;
return NET_SOCK_BSD_ERR_RX;
}
else if (0 == totalLen)
{
/* we've read the whole file and we can leave*/
*p_err = NET_SOCK_ERR_CLOSED;
}
return totalLen;
}
It is important to note that the above code returns an error when the end of the file (EOF) is reached. This happens because NetSock_RxData is invoked within a processing loop, and the error serves as an indicator to the caller that this "socket" has been closed.
When fuzzing an application, it is crucial for the fuzzer to differentiate between a clean exit (normal program termination) and a crash. Additionally, the program should terminate after processing the fuzzed input. Therefore, I needed to make another code modification for fuzzing purposes, ensuring that the program exits after the file has been read and processed, resulting in a "normal" termination.
Without this modification, the application would continue running in a processing loop, causing the fuzzer to mistakenly count this as a hang rather than a normal program termination, leading to false-positives for hangs.
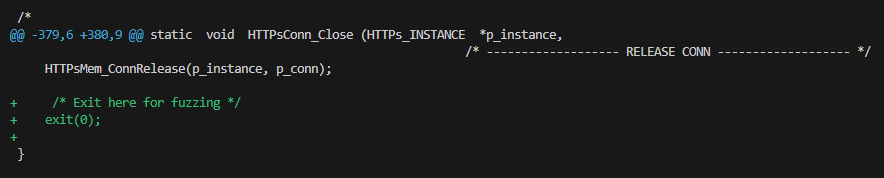
By placing the exit in this location, it will be called during the typical execution flow of closing a connection. And, as noted above, when the error code NET_SOCK_ERR_CLOSED is returned from NetSock_RxData, it triggers the HTTPsConn_Close function, which subsequently terminates the program's execution.
Memory errors
A major benefit of porting my µC/HTTP-server application to run natively on Linux is that I can compile my application with AddressSanitizer. AddressSanitizer, or ASAN, is a compiler feature in GCC and Clang that can detect memory errors in C/C++.
This can be a very valuable tool when used in conjunction with fuzzing to reveal software vulnerabilities. When ASAN is enabled, the application will crash when a memory error is encountered.
Things like use after free, NULL pointer dereference, and buffer overruns will cause an immediate crash even if the test input would not have normally crashed the program. When ASAN causes a program to crash, it’s like an alarm bell going off for a vulnerability researcher (“Look over here, there are problems in this section of code!”). I wanted to use ASAN when running my fuzzer, but it didn’t work straight away for heap memory in my µC/HTTP-server application. This is because µC/OS provides its own heap implementation.
ASAN works by tracking heap memory allocations made with glibc malloc, but my application doesn’t use malloc at all. The simplest solution that I produced was to add preprocessor macros to detect when the application was being compiled with ASAN and redirect the allocation to glibc malloc. Here’s an example of what I mean:
void *Mem_DynPoolBlkGet (MEM_DYN_POOL *p_pool,
LIB_ERR *p_err)
{
#ifdef __SANITIZE_ADDRESS__
p_blk = malloc(p_pool->BlkSize);
if (NULL == p_blk)
{
*p_err = LIB_MEM_ERR_POOL_EMPTY;
return(DEF_NULL);
}
else
{
*p_err = LIB_MEM_ERR_NONE;
}
return (p_blk);
#endif /*__SANITIZE_ADDRESS__*/µC/OS provides developers the capability to define constraints on the heap's location and utilization with its specialized heap allocator. This feature is particularly useful in systems with limited memory, where developers require fine-tuned control over memory allocation. However, since my application is running on Linux, I'm not constrained by memory limitations, and I have access to the standard glibc malloc function. Simply calling malloc within Mem_DynPoolBlkGet works because the caller of Mem_DynPoolBlkGet doesn’t care about the specific memory location of the pointer that's returned. Rather, it expects the pointer to reference a chunk of memory that's ready for use and meets the minimum size requirement. By making this minor adjustment to the code, I enabled the Address Sanitizer (ASAN) features I wanted, without affecting the rest of the application's functionality.
Vulnerability highlight
To this point, we’ve made strategic modifications to µC/OS code, creating a software-only fuzzing solution capable of running natively on Linux and accepting input from a file. The approach we discussed here has proven its efficacy by uncovering five unique vulnerabilities: TALOS-2023-1725 (CVE-2023-24585), TALOS-2023-1733 (CVE-2023-27882), TALOS-2023-1738 (CVE-2023-28379), TALOS-2023-1746 (CVE-2023-31247) and TALOS-2023-1843 (CVE-2023-45318).
When disclosing these vulnerabilities, I discovered that much of the µC/HTTP-server codebase is shared across multiple products. Other affected products are the Silicon Labs Gecko Platform and Weston Embedded Cesium NET. All the vulnerabilities discussed here have been reported to the manufacturers in accordance with our Coordinated Disclosure Policy. Each of these vulnerabilities in the affected products has been patched by the corresponding manufacturer.
The following Snort rules will detect exploitation attempts against these vulnerabilities: 119:201, 119:281, 1:12685, 1:39908. Additional rules may be released in the future and current rules are subject to change, pending additional vulnerability information. For the most current rule information, please refer to your Cisco Secure Firewall or Snort.org.
The next installment of this series will describe the complexities of handling multiple requests per test case — an enhancement that holds the potential to reveal even more vulnerabilities.